いや、ほんとになんでなんだよ。意味わからんよ
普通、クリック、ダブルクリック、長押しくらいはあるろ。ていうかスイッチをボタンに変えるってほぼそれが狙いなんじゃないんか。Proモデルのみの差別化要素なのに機能性変わらんやんか
そして各メディアは、カスタマイズ可能なアクションボタンが搭載ッ!クール!とかしか言わないのはなぁぜなぁぜ
いや、ほんとになんでなんだよ。意味わからんよ
普通、クリック、ダブルクリック、長押しくらいはあるろ。ていうかスイッチをボタンに変えるってほぼそれが狙いなんじゃないんか。Proモデルのみの差別化要素なのに機能性変わらんやんか
そして各メディアは、カスタマイズ可能なアクションボタンが搭載ッ!クール!とかしか言わないのはなぁぜなぁぜ
ちょうど良い話があったので。
見かけたので少し言及するけど、よく「イ」のパターンでアラートダイアログないしモーダルビューを作る人がいるのだけど、クローズボタンとキャンセル/OKボタンを設計としてきちんと区別するべきだし、特に深い考えがないなら、クローズボタンはこの場合無くした方が良いです。 pic.twitter.com/O62XOPpt2U
— usagimaru ⌘ (@usagimaruma) 2023年7月29日
これ、自分の引用ツイで書いたけど、正解はロなんですよね。
このダイアログの目的はユーザーに進むかやめるか選ばせること。
進む/やめるが同列に扱われてるロが圧倒的正解。ハは進む/やめるが同質のUIでないのでデザイン意図が伝わりにくく不適。イはやめるボタンが2つあり混乱を招き、かつロハに対する利点が全くなくNG。二は進むやめるの選択ではないので別物
異論はほとんどないくらいシンプルな話ですが、実開発でこれいうと反論されることが結構あります。
曰く
などなど。ひどいのになると競合他社はどうだとかNetflixはどうだ(なのでそれが正しい)とか言い出す人もいる。
こういうことを言い出す人はデザイン成果物を絵と捉えているフシがあるようで。
絵が似ている、絵として統一感がある・ないという発想。自分が好きだ、嫌いだ、みんなこれが好きに違いない、流行ってる、美的感覚でいうとどうだ、などなど。
しかし、言うまでもなくダイアログとモーダルウインドウはその存在目的が異なる。Yes/Noを選択させるUIと単に情報を提示するだけのUIも別物である。
UIはシステム上の目的を達成させるための手段であり、最大多数が最も認知しやすい形態を取るべきだ。
〇〇な目的なので、XXで有ることを認知しやすいこういう形やレイアウトにして、〇〇の目的を間違いなく達成できるようにする、と論理展開できるはずだし、出来ないのは間違いである。その展開に「より穴がない」のが良いUIということになる。
冒頭に上げた例はロ以外は妥当な論理を構築しにくい/ロを上回る論理展開ができないから、正解はロと言い切れる。
この、ちゃんと論理展開できるというのは基本中の基本であるし、最低レベルのルールである。われわれは芸術品を作っているのではないのだから。
どうしてそれが良いのですか?と聞かれて明確に答えることができない人間はデザインを語る資格がない。
でもどういうわけかそれができない人は一定数いて*1*2、正直話す価値すらないので、情報デザイン技師みたいな資格なりなんなりで弾いてほしいという今日このごろである。
Gitは、思慮浅い下々のわれわれがしょうもないシステムの変更とリリースを管理する、というシンプルな目的に対しては難しすぎる。
特に妥当なマージ戦略がひとつに定められないことが致命的すぎる。
PullRequestのメリットだけを享受できるシンプルなSCMが出てきてほしいな。
えっそんなところから?という声が聞こえてきそうだが、そんなところからなのだ*1。
この基本的なとこでつまづくひとはかなり多いし、その場合の説明が超面倒くさい。
PCを理解しているほとんどの人にとってファイルシステム上のファイルこそが永続的なもので「裏に謎の仕組みが潜んでいて永続的であるはずのファイルがコロコロ切り替わる」というモデルには馴染まないのだ。天才たちはすぐに新概念を理解できるかもしれないが、凡人は既成概念に囚われるのだ。ファイルは虚像で、本体は.gitの中にしかない、なんていうまどマギみたいな話はビビるのだ。
zipファイルをダウンロードしてフォルダに解凍するように、リポジトリをcloneしてフォルダにcheckoutできるようにすればよかった。フォルダとブランチが1対1のほうが全然よかった。フォルダの数=ローカルリポジトリでの展開ブランチ数となったほうが全然わかりやすかった。
しかも、ワーキングフォルダ内のファイル群が完全に切り替わるならまだしも、git add前のファイルは継続配置され続けるところが更に誤解を生みやすい。ローカルで保存しといたはずのファイルが消えちゃいましたとかって悲劇が生まれる。
最初のつまづきだけならまだしも、この辺の仕組みが実は理解できてなくてなんか起こるたびにcloneからやり直す、みたいな人も一定数いるように思う。
もちろん、現状のモデルもデフォルトでディスク利用量が少なくなるなどのメリットはある。毎日数十もの新ブランチを確認しなければならないなら速度的メリットも大きい。しかし、そういうのはオプション化してマニアックな人だけが使えば良いとおもうのですよ。

Gitブランチの解説文にはたいてい上のような図が載っているが、こういうきれいなツリーを表示するツールがない。
ほとんどの開発者はメインブランチdevelopから分岐したfeatureの担当であり、developとfeatureの状況を同時に見たいはずだ。developを幹として、featureを枝として。大抵の場合たくさんのブランチが並行しているのでブランチを絞りたい。大抵の場合たくさんのコミットがメインブランチに行われているので分岐近辺以外は省略してみたい。
できない。なんでや。
いまんとこ一番理想に近いのはVS Code拡張のGit graphかな?ほとんどのツールはなぜか2つのブランチだけに絞って表示することすらできない。
Gitはややこしいのでさまざまな状況でツリーを表示させて自分の意図通りの構造かを確認したくなるはずだ。あまり理解していないならなおさら実地で確認すべきだ。でもその構造をいい感じに確認するツールが少ない。
かくしてGitのブランチ構造を深く理解する術は失われ、いつまで経っても、〜なんとなくコミット・プルリク・競合で大慌て〜の状況は繰り返される。
こんなふうにして大混乱する。実際は※ついてるところは間違いなんだけど、詳しい知識がないと対応できない。
で、一番ヤバいのは、マージ作業自体はほぼほぼコード作成者本人しかできない、ってとこ。誰かがヘルプしたとしても、ここ変えた?変えてない?って考えてどっち採用するか決めるのは本人しかできない。詳しい人が巻き取ることはできない。マージの競合なんてしょっちゅう起こる作業のたびにこういうことで混乱する。
どうにかならんものか。競合を起こさないような運用*2みたいな意味不明なルールを決めることとかもある。うそぉ?と思うかもしれないけど、マジです。
こう書くとマウント野郎がCLI使えないやつは素人、とか言いだしそうだが素人だしこんなもののプロになりたくないので放っておいてください。ていうかGitをCLIだけでやるって実用上可能なの?diffとかつらくない?
で、決定版のツールが全然ない。一番まともでマルチプラットフォームなのはSourceTreeか?でもまだ不十分。
ツールによって翻訳が入ったりコマンドとの対比内容が違ったりで同じことが違う表現になっててわかりにくいことこの上ない。
結局求められるのはツリーの見やすさと競合解消のしやすさだが、決定版がない。Windows民はトータスGitしか使えないこともおおい。ググればコマンドばかりで自力で成長できない。
そもそも、もとはといえばgitコマンドの構成がわかりづらいのが原因の部分も多いので将来にわたって改善しなさそうなとこがつらい。
今までの話は、単に勉強不足だと言って切り捨てることができるだろう。
しかしこれは違う。宗教論争だ。一般にmerge vs rebase論争と言われている?のかな?知らんけど。ただしこれはmergeとrebaseだけの話ではなくて多くの問題を含んでいる。
merge派の極みは、一切のrebaseをせずmergeのみで競合を解決するというもの。rebase派の極みは、ブランチでのすべての変更をsquashしてマージ直前のコミットからrebaseするというもの(すべてが下記のようなコミットツリーになる)
* Merge branch 'branch3' into 'develop' @user1 |\ | * Fix zzz |/ * Merge branch 'branch2' into 'develop' @user1 |\ | * Fix yyy |/ * Merge branch 'branch1' into 'develop' @user1 |\ | * Fix xxx |/ *
前者はコミットツリーが汚くなりすぎて何がなんだかわからなくなりがち。後者はあらゆる履歴が1つにまとめられるので経緯情報が失われる。
結局のところ、起こったことはすべてそのまま記録すべき(経緯が大事)派と、なにをもとになにを修正したかを明快にすべき(結果が大事)派の争いであり、どちらも正しい。だからタチが悪い。
大抵はrebase派のほうがGitに詳しくてmerge派はrebase派の言っていることが理解できてないことも多い。しかし、rebase派は当然のようにpush -fの使用を強制するためmerge派からすると「ただでさえ難しいGitのさらによくわからない手順を覚えた上で禁忌とされる『他人のコミットを壊す』恐怖に怯えなければならない」ため受け入れ難い。
これでさらに、rebase派が煽り気味にマウントとったりすることもまれによくあるのでろくなことにならない。そして根本的にどちらの言ってることも正しいので全然落とし所がみつからない。嗚呼なぜこんな苦労をせねばならんのか。
gitは分散リポジトリなので、中央集権サーバーを持たずにお互いpull pushをして同期し合うモデルが可能だったはずだ。
こういう運用をしてたことがあったのかは知らないが、2022年現在、ほぼ全ての人がサーバークライアントで使ってるだろう。githubみたいな「originたるサーバー」と、自分だけのローカル。
Git管理で最も役に立つ機能はプルリクエストだろう。安心安全なシステム開発にあたって変更をコントロールしレビューの強制を実現できる仕組みは素晴らしい。ほとんどの人はプルリクレビューのためにGitを使っているのではないかとすら思う。
先に示した運用ルールに則したマージ戦略の徹底やPRを介さない直接pushの禁止、歴史改変の禁止などをブランチ単位でコントロールできる機能は、開発現場の秩序維持にとても役に立つ。
素晴らしい。しかしこれらは全部GitHubの機能じゃねえか!GitHubなかったら分散という名のただのややこしくて理解しづらい仕組みじゃねえか!
Gitをよく知ってる人ならご存知なように、ブランチは「枝」という名前ではあるが、実際には全然枝じゃ無い。コミットである。
ほとんどの人がメンタルモデルとして枝分かれの樹形図をイメージするが、実際はコミットをたどることによって「結果的に」ツリーが構築されてるにすぎない。
樹形図表示ツールの決定版が出てこないのも、樹形図を分岐や結合に絞ってうまく意図とあうように表示しにくいのも、根本的にはこれが影響している。このモデルはGitの核であるため一生解決しないことがほぼ確定である。つらい。
いやわかるよ。Gitにとってハッシュこそが肝なのはさ。
でもあえて言わせてもらおう、ブランチ名+連番とかでコミットが一意に表せてほしい。rev123まで戻して再デプロイして!とか言いたいのだ。df87aj2まで戻して!とかなんやねん伝えにくいわ
原点に立ち返って考えてみよう。
多くの人にとってGitは手段である。安全安心なソフトウェアを作ることが目的で、そのために変更管理が必要だ。変更管理(とそれにまつわるレビューや承認や修正の管理)をしやすくしたいのである。
その目的に対して、Gitは難しすぎる。メンタルモデルと実体は合わないし、メンタルモデルを正確に反映するGUIツールはないし、どちらも正しいが相反する2つのマージ戦略がある。
われわれは、Gitについて詳しくなりたいわけではない。さいきょうのGitFlowを作りたいわけでもない。Gitが開発者の嗜みの一つとして当然のように存在することでシステム開発の間口が狭くなることを憂慮している。
どうしてたかがソース管理のためにこんな難しいものを理解しなければならないのか。欲しい機能はプルリクレビューだけだ。ブランチ作るのが早いsvnがあればそれでも全然いい。
Gitは神が戯れにつくったツールで、人類に広く普及するには早すぎる。
最近、猫も杓子もredmineじゃないですか。そうでもないですか。そうですか。redmine使い始めると現れる困った人についてまとめます。*1
とても多い。コメントは書くが、ずっとステータスを新規(初期状態)のままにしておくヤーツ。
なぜそんなことになるか理解できない。どれが終わってるのか自分でわからなくて困らないのか。
ステータスは完了にするが、進捗率は100%にしないヤーツ。
これはシンプルにredmineの設計が悪い。完了したら100%になるのは当たり前だ。プラグインで解決できる問題なので導入すべし。
明日打ち合わせしましょう、とか、後で電話します、とかまで書いちゃうヤーツ。いやチケットの事象がどうなるかだけ書いてよ。
なんでもチケットに書いちゃうヤーツと同類であることが多い。
結局対面の打ち合わせで自分は納得して満足して、結果を書かない。外から見るとチケットの事象がどうなってるかわからない
redmineは1事象1チケットが基本であるが、コメントの途中で「そういえば〇〇はどうなんです?」などと違う話を始める。
別件としてチケットを切ってください、と何度言われても繰り返すのが特徴。受け手は話変えられたとしてもチケットで返答するしかないのでタチが悪い。
この手のヤーツはツールによらずその傾向がある。メールでも話をまぜこぜにして今いくつ話が進んでるかわからんことになりがち。
100とか超えちゃう。常識で考えて、1つの事象に対して100回もやりとりが発生する可能性は薄く、なにかをまちがえている。基本的に話コロコロ変えるヤーツが違う話を延々と続けてるパターンが多い。
メールにTODOフラグつけるとか、印刷した紙に付箋つけて管理するとか、自分用Excelをローカルに持ったりとかしてそっちでステータス管理してしまう。
ので、redmine側ではステータス変更しないヤーツになってしまう。
文明の利器をつかいこなして!
バグが発生してから、直して、レビューして、修正確認して、QA確認して、リリース決めて、、、、という流れを1つのチケットでやろうとしちゃうヤーツ。高機能なバグトラッカーから移行した人がやりがち。redmineはチケット設計にかなり自由度があるので、こういう設計も間違いではないが、チケットのライフが短いことを前提に終わった終わらないを管理するプラグインが多いため、プラグインエコシステムをフルに享受できない可能性が高い。
ライフが長くなると当然フェーズごとに担当者が設定されるため、〇〇担当者というカスタムフィールドが増えて一覧性検索性も悪くなりがち。
ライフが長いチケット作るヤーツにありがち。newからいきなりcloseに行けないように、などのルールを厳密に作りすぎる。
大抵例外系をすべて網羅できずに死ぬ。
しかし作り手的には「ぼくがつくったさいきょうのフロー」という自負があるため面倒なことになりがち。
ちなみに、利用者にとって「問題は解決してるのにわけのわからんシステムのせいで自分の手から離せない」というは非常に大きなストレスである。
redmineのデータをエクスポートして色分けしたりグラフ化したりする便利ツールを作ってしまう。
そこには情報が集まっているので書き漏れや納期遅れなどはその人にはわかる。だから毎日毎日みなの不備を指摘するredmineおじさんとなる。
本人は開発プロセスを下支えするスーパーパーソンのつもりだが、利用者側としては毎日毎日ちまちま指摘されてウザい。状況を改善したとしても、本当に改善されたかはちまちまおじさんしかわからないのでストレスが溜まる。
もちろん改善されたはずのものが実は改善されてないとちまちまおじさんは怒り出すので、さらに厄介なことになる。
ツールは共有して誰もが恩恵を享受できるようにしましょう(ただしやっつけで作ったツールで本人以外にはまともに使えないというパターンは大いにある)
おっと最後に特大のブーメランが。redmineはこう使うに決まってるでしょ、とか、そんなこともわからないんですか?などと上から言ってしまう。
どんな利用者であっても、そもそもプロジェクトの関与者は敵ではなく協力者である。それぞれの関与者にはそれぞれの仕事がある。ツールを使いこなすのが仕事ではない。だれもが進捗管理ばかりしているわけではない。
くだらない上から目線のせいで心象を概して、どれがマスターなのかもわからないExcel地獄に戻りたいのか? リスペクトを忘れるな!
*1:「出、出〜redmine使いこなせな奴〜」というタイトルにしようと思ったが、このフォーマット自体がかなり死語なのでやめた。最近とんと聞かないな
6/15に今年2月から3月に連続して起きたみずほのシステム障害調査報告書が発表されました。部外者からすると結構読み物として面白く、また示唆に富んでいるので感想を書きます。
自分がアプリエンジニアなのでその方面の観点が多め。
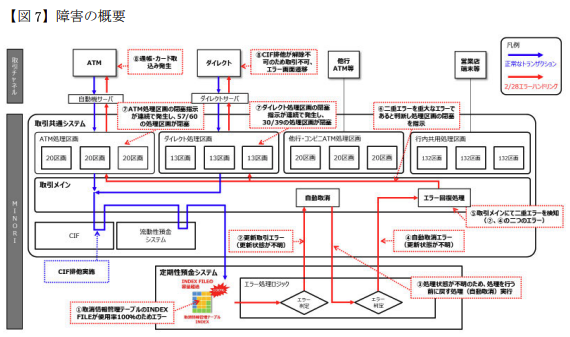
2/28 9:50に大量データ登録によって定期性預金システムにおける取消情報管理テーブルがDiskFull(実際はオンメモリのINDEX格納領域の不足)になって全死
→ 取消情報管理テーブルが全死なので、定期性預金トランザクションの取消そのものができなくなる(2重エラー)
→ この2重エラー状況を検知した上位システムにより防御機構が作動し、ATMやダイレクトチャネルの流量制限が行われる
→ 流量制限されたATMでカード飲込みが発生
システムには2種類の防御機構があったようである。
1つ目は、1系統で同じサービスが30回エラーになったら、そのサービスそのものが使用できなくなるようにメニューから自動で消す「取引サービス禁止機能」(P.51)。今回だと、定期性預金サービスが全死なので、ATMのメニューから定期預金関連のメニューが消えていった。なんかちゃんと動いてないサービスあるからそれ使えないようにしといたろ、的なヤツ。
2つ目は、2重エラー(≒パーコレートエラー)が5回発生したときに、そのきっかけとなった処理区画を自動で閉じる機能(P.46) 。なんかシステム全体ヤバそうだから入り口を閉めて全体に負荷かからないようにしたろ、的なヤツ。
なお、システム全体は3系統あり、1系統ごとにATM処理用に20区画が用意されているとのこと。多分1区画ごとに複数個のトランザクションを走らせることができると思われる。「系統」は全く同じシステム構成が3個ある(負荷分散と可用性確保用)と思われる。そのへん詳しく書いてなかったのでわからんが。
で、今回は前述のように定期性預金サービスが全死だったので、もしなにかするなら、前者の防御機構を強めてなるべく皆が定期預金系サービスを使えないようにする必要があった。
が、あろうことかこの制限を30回→999回に緩めてしまった。この結果、皆が(抑制されていた)定期預金系サービスをつかえるようになって、それが全部エラーになって、後者の防御機構発動→ATMの停止祭り、となってしまった。
障害の真っ只中で混乱はあったのだろうが、それを差し引いても無能な対応だったと言わざるを得ない。なお、作業の指示と実行は11:37-12:08の期間で行われているが、11:30の時点で(定期性預金サービス内の)DBのDiskFullという根本事象が常務に報告されているので、この時点で常務に整然と報告できるほどに根幹は見えていたと思われる(P.38)。
なのになぜw この失敗が致命的である旨が報告書で数パターンのグラフwで示されており(P.41,53)、そのあと結局定期性預金サービスは完全に切り離したので、この措置矛盾しすぎだとか、昔うまく行った記憶をもとにノリでやりました的なこともバラされていて(P.76)もはやフルボッコ状態ww この指示者の行く末が気になるところである。
本件、先に述べたとおり根本事象はDBのDisk(オンメモリ格納領域)Fullである。領域拡張が終わったのが14:54、これを利用する定期性預金性サービスを16:22に再開完了している(←起動に1時間半もかかるのな)。
どうもここで一旦障害対応が終わったと思ってたフシがある。16:37から障害の過程でロックされた顧客ファイルの解除を試みており、つまり事後処理を始めてることが見て取れる。
一方、ようやく防御機構2によってATM処理区画が閉塞がされてたことを認知したのは17:10である。この間、だいぶ混乱したんだろうなあと。「ダメです!ATM回復しません!」「そんなバカな」みたいな。エヴァかな?ぜひ再現ドラマを作って欲しい。
こういう安堵からの再混乱みたいな話好きなんですよね。完全に他人事だから言えますが。
思うに、対応担当者は防御機構2(パーコレートエラー検知によるATM閉塞)を知らなかったのではないかな?定期性預金でのエラー→ATMの閉塞と直接的に考えたのではないだろうか。なので、定期性預金のエラーが検知されないようにするために、おもしろポイント1の対応を行ったのではないかと。
まあ実際にはエラーが検知されないようにする対応ですらなかったわけで、やっぱり草生える対応なわけですがw
報告書にはさまざまな側面における原因が記載されている。
原因DiskFullだったわけなので、当然「DiskFullになる可能性を予期してレビューや事前確認を行うべきだった」てのは出ると思うんです。が、これ現実的じゃないと思うんですよね。インポート対象のテーブルがDiskFullになったのならともかく、「定期性預金サービスの、共通処理を担う取消情報テーブルの、INDEX領域がオンメモリに格納されかつそれが当日の処理量に応じて増加する性質に基づき、さらにメモリ利用量の監視警告が見逃される可能性」を予期できるか?という。
ひとはいつでも間違いを犯す、という観点に立つとあらゆる内容をルール化するとか運用体制をガチガチにしばるのもあまりイケてないなあと思います。間違いを犯しても大丈夫な仕組みを構築することが大事と思うのです。
なのでその観点でこれはできたやろという"現実的"な対策を2つ上げたいと思う。
ま、これよね。P.69の原因(オ)として記載がある。前述の通り防御機構は2種類あって、定期サービスやばいから定期サービス止めとこ、と、なんかわからんがやばいから全部止めとこ、の2つ。
その内訳が↓(P.47)
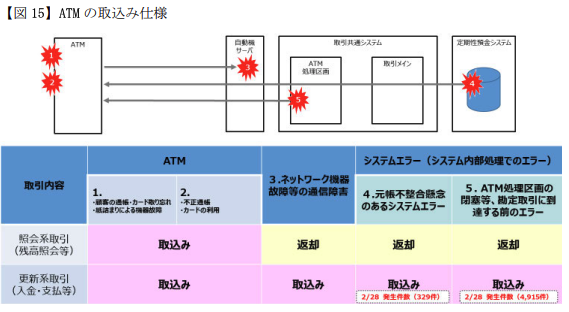
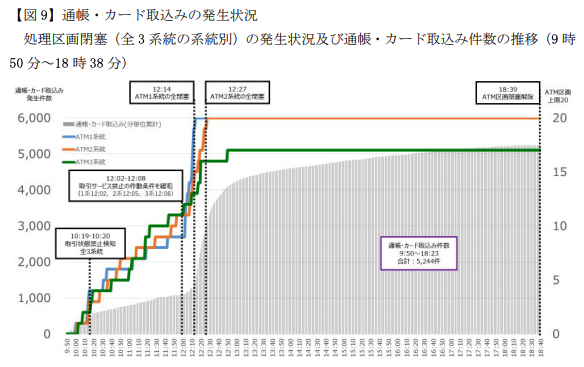
要は、「なんかやばいから全部止めとこ」の方で引っかかって飲み込まれた人が4915件と大多数。
この後者のほうがカード戻す仕様であれば、障害数が5244→329件に抑えられた上に、「定期預金サービスでエラーが発生したので、定期預金サービスを使おうとしたお客様の資産保護のためにカードをお預かりしました」と一応辻褄がある説明ができたはずなのだ。
最もあかんのは、過去3回も同様のトラブルを起こしていた(P.69)のになにもしてなかったこと。この大障害の発生後に速攻直した(P.133)らしいけど、なんだ速攻直せるんだな、最初からやっとけやそういうとこやぞと思わなくもない
人間だから、悪い仕様に気づけないことは多々あるだろう。でも同じトラブル3回も起こしたら、さすがになんかおかしいと気づけよ、と思う。
P.67(イ)として記載あり。
原因は定期性預金サービスの取消情報テーブルがDiskFullになったことである。明確に記載がないが、おそらくなにか処理を実行する前、最初に実行前情報をコピーしておく(そして戻せるようにする)情報テーブル/機能だと思われる。(DBのロールバックが効かなかったときの保険的機能である旨の記載がある)
それで、この最初の処理が死んでたので事実上なにもできない状態だったと。処理エラー時に整合性が失われたか否かを返す機能があり、それを元に取消を行うか否かを判断しているのだが、それがバグってて常に取消処理を要求するようになってたとのこと。そしてその取消処理もコケるので2重エラー≒パーコレートエラーとなって、ATM閉塞を招いたと。
ここも、うまく動いていれば、障害数が329件で定期預金サービスを使おうとしたお客様のみへの影響で抑えられたはずなのだ。
取消情報テーブルの名のごとく、これはシステムがなんかやらかしちゃったときの最後の防御機能なので、特に重点的にテストすべきだったし、SPOFとなりえる点も踏まえるとオンメモリINDEX保持への設計変更も慎重にすべきだったように思う。
ここが原因だったから云々じゃなくフェールセーフ機構だからという観点が大事。
人間はいつでも間違える、だからフェールセーフがある。そのフェールセーフがさらに間違えないように狙いを絞って慎重にレビューとテストをすべきだった、と思う。
---
人はいつでも間違える。締め付けて管理すれば何でもできるわけではない。未来をすべて予測できるわけでもない。だから、間違いに気づいたら改善しよう。間違いが起こっても大丈夫なような仕組みだけはしっかり作ってみんなで保証しよう。
この辺がうまくできてなかったんだろうなあと思うし、これがうまく回るような"現実的"でシンプルなルールができれば良いと思う。間違ってもチェックリストが何十枚にもなるとかそういう無理ゲーな対応になりませんように。
みずほの話になるとなぜかネット上で知ったかして適当なこという人が増えるのでそこへのコメントを。
あらすじ部分にも書いたように、特定サービスのDB DiskFullが原因であり20万人月システムことMINORIのバグではない。
報告書要旨版の原因欄の一番上にも「MINORIの構造、仕組み自体に欠陥があったのではなく、これを運用する人為的側面に障害発生の要因があった」とはっきり書かれている。
実は最初の1回以外、残り3回のうち2回はハードウェア故障を検知して自動切り替えしたという事象で、どちらかというとうまく動いた事象である。
残り一回は初歩的なプログラムミスだが、まあ正直よくある話で、全部一緒にして4連続障害として叩かれたのはかわいそうに思う。
めちゃくちゃある。
リーダーシップのリの時もみえない。公式な緊急対応体制が構築されたのが事象発生から7時間以上経ったあとという1点のみで辞任はやむなしである。全く危機管理体制が機能していない。就任から3年以上こんな感じだったのに、再発防止策の徹底のために続投とか片腹痛い。この報告書書いた人に頭取になってもらえ
まあ、わかるよ。言いたいことは。
でも有事に断片情報を元に本当に正しい行動を取れるだろうかと。顧客に情報を伝えるにしても、それが間違っていた場合どうすれば、などまで考えるとなかなか動き出すのはつらそうなのもわかる。
個人的にはこれ系のアプローチよりも問題そのものが起こらなくできたり局所化できたりできるように仕組み作ってくべきなんだろうなと思う。
みずほ銀行のシステム障害、データベースの運用ミスが障害の発端だったんですが、これだけDBがバラバラだと、そりゃあ運用も大変かと。詳細は記事をご覧下さい https://t.co/WRUEd5JN54 pic.twitter.com/GE984QR1F0
— Atsushi Nakada (@Nakada_itpro) 2021年6月15日
たしかにDBがバラバラで運用が大変そうだが、今回の直接の事象とDBの多様性は関係ないように見える。
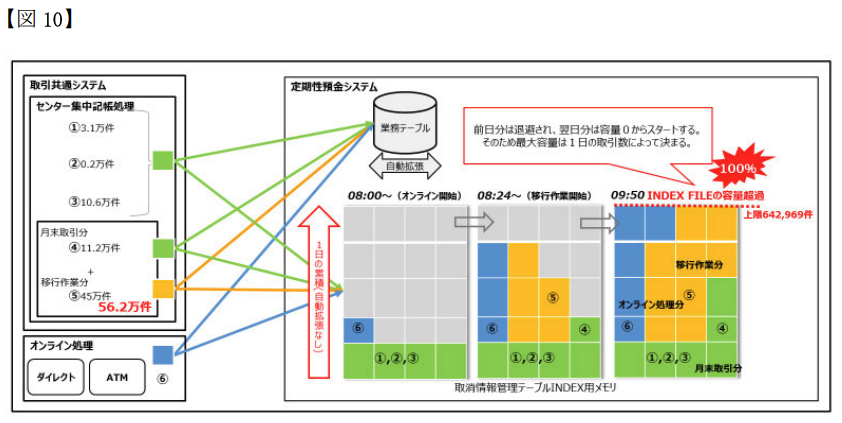
が、そもそもの根本事象である取消情報管理テーブルのINDEX FILE容量超過。報告書内に何度も書かれているように、テーブル本体ではなくてINDEXだけがメモリ上に常駐しているらしい。そして、前日分のINDEX容量は退避されて、当日の処理量に応じてINDEX容量が増えるらしい。これって普通のDBMSでできる話なんですかね?いまいち直感に反する話なのですが、前日分までが退避領域(HDD,SSDなど)にあって当日分だけがメモリにあって、それらが透過に扱えるってこと?そういうの、今は普通なの?
そもそも取消情報管理テーブルの名前からして一時テーブル(グローバルトランザクションの生存期間でのみ有用な一時データ)みたいなイメージですが、それが日をまたぐ事があるってこと?いまいちよくわからない。このへんの「わからなさ」がDBMS固有の機能だったり固有の設計制限であったりするなら、多様なDBMSを運用している副作用かもしれない、とは思いました。
パーコレートエラーってなに?
どうみても専門用語(IBM用語?)なのになんの解説もない。最初は2重エラーのことかと思ったけど、2重エラーのようなシステム全体の非安定稼働を想起させるような重大なエラー/イベントのことっぽい
転職活動でオンラインホワイトボードコーディングテスト(zoomでつなぎながらテキストエディタ共有サイトでコードを共有するパターン)をやったので、その心得を書いていきます。
ちなみに結果は、超簡単な問題だったにもかかわらず、テンパってしまい面接官の言われるがままコードを書いてなんとか完成させるもののもちろん落選というもので。
結構行きたかった企業の1次面接だったので、だいぶ落ち込みました。ということなので、心得というか、失敗談ですね。
あとになって思い返すと、これが全てだったかな。お題が与えられたときに、どういう雰囲気で解こうとしているか、どういう処理をして、結果がどう変化していくと想定しているのか、説明すべきだったと思う。
多分ホワイトボードがあれば、配列とか集合とかの絵を描いて雰囲気説明するんだろうけど。
これをしないと面接官となにをどうやろうとしてるかの意思共有ができなくて、(自分からすると)的外れなツッコミを受けて混乱することになります。
あと、多分「物事を論理的にとらえてるか」とか、「人にわかりやすく説明できてるか」とかの採点指標になってる気がします。知らんけど。
最悪、説明がうまくできてれば多少コードがあれでも通るのではないかとかも思ったり。ま、面接官じゃないんで知らないですけど。
コーディング中は、面接官がかなりサポートしてくれます。あれ?そこ〇〇が抜けてない?とかそういうことを言ってくれる。すごく親切。
親切…なんですが、これはめちゃくちゃプレッシャーになります。特にどうコーディングするかをうまく共有できてない状況だと、「あれ?なんか言われてるけどなんのこと?どこのこと?よくわからない。スルーするのもおかしいし。とりあえず直すけど、あれ?ここをこうすると全体はどうなるわけ?なんだ?なんだ?」となります。
そもそも、相手方だけが一方的に「答え」を知っていて、即座に口出しはしてくるけれども正解を教えるわけでもない、という状況はわりと特殊です。実務上、経験したことがない人もおおいとおもいます。
ペアプロだったら「一緒に考える」が出発点だし、わかんなかったらわかる方が書いてから解説しますからね。そもそも、コーディング複数人でやったことある人自体も少ないですよね。
このシチュエーション、練習しようがないのが特にアレなんですが、ともかくそういうことが起こるという心構えは必要でしょう。これ、面接官本人が親切のつもりでやってるのがさらにたちが悪い。正直、だまっててほしかったです。
就職転職の面接だと、AtCoderやLeetCodeみたいな競技プログラミングサイト(以下競プロ)チックな実技試験もあります。この手のサイトで練習しといた方がいいという意見もよくみますが、ちょっと微妙です。
理由の1つ目は、ホワイトボードテストの問題は競プロの問題と比べて多分かなり簡単であろうということ*1
その場でロジック考えて説明して、話しながら改良して、という性質から考えると、広がりはあるものの書ききること自体は簡単な問題が出ると考えるのが妥当でしょう。
なので、競プロで練習しまくっても本番が簡単すぎて練習の意味がなくなる可能性があります。
2つ目は、競プロとホワイトボードテストは作業手順が異なること。競プロは、コンパイルもテストも通す必要があるけども、1人で黙々進めることができます。ググることもできるし、とりあえず書いてみてからテスト通すことを目的にバグつぶししていくこともできます。
わたしも今回初めて気付いたのですがこのタイプのコーディングをしてます。ザクっと雰囲気で書いてからリファクタしていく、という。
対して、ホワイトボードでは、まず概要を説明してからツッコミに耐えながら描き続けなければなりません。コンパイルが通る必要は全くないですが、コードで正しく意図を表現できる必要がありますし、要点だけをコード化しなければなりません。
AtCoderで難しい問題が解けるようになっても、それより遥かに簡単な問題の、要点部分だけを書いて、それをわかりやすく説明しなければならないですし、そもそも書き始める前に概要を言わなければなりません。
その辺意識して競プロで(たとえばコード書く前に口で説明してみるとかそういう手順を入れて)練習するなら良いのですが、ただ単にドリル的にサイトの問題を解きまくると本番で思わぬ落とし穴が来るかもしれません。
あまり答えは出てないですが、面接時の状況としてはペアプロがいちばん近いのかなあと。スーパープログラマーに簡単な問題出してもらって、横でつっこまれながら書いていって慣れる、とか?
まあ、あとはホワイトボードテストを依頼された時点でその会社はご縁がなかったとして諦めるとか。自分はいまはこの気持ちですね。あまりに出来が酷かったので、面接直後に落ち着いて書き直したら5分で完成できましたし。いまだになぜできなかったのかよくわかっていない。ただただ苦手意識だけが植え付けられてトラウマです。
参考になれば。
*1:n数1であれですが